Qué pasó, por qué afectó a medio internet y cómo blindar tu infraestructura con buenas prácticas, multirregión y planes de continuidad
Qué ocurrió y por qué importa
Este 20 de octubre de 2025, un fallo en Amazon Web Services (AWS) afectó a miles de servicios y aplicaciones alrededor del mundo durante varias horas. Plataformas populares de consumo y herramientas empresariales experimentaron interrupciones, demoras y errores intermitentes. Informes iniciales señalan que el incidente se originó en US-EAST-1 (Virginia) y estuvo relacionado con componentes internos de red y DNS/balanceadores, lo que evidenció nuevamente cuánto depende la economía digital de unos pocos proveedores de nube. (Resumen de medios: Reuters, The Verge, The Guardian). (Reuters)
Por qué te afecta aunque no “seas tech”
- Cadena de valor completa: si tu pasarela de pagos, tu CRM o tu web dependen —directa o indirectamente— de AWS, el impacto te alcanza.
- Efecto dominó: una caída regional puede provocar colas, reintentos y saturación en sistemas que sí están “arriba”, degradando su rendimiento.
- Confianza y ventas: minutos de indisponibilidad pueden traducirse en carritos abandonados, tickets sin atender y usuarios que no vuelven.
Lo que esta caída nos recordó (consejos accionables)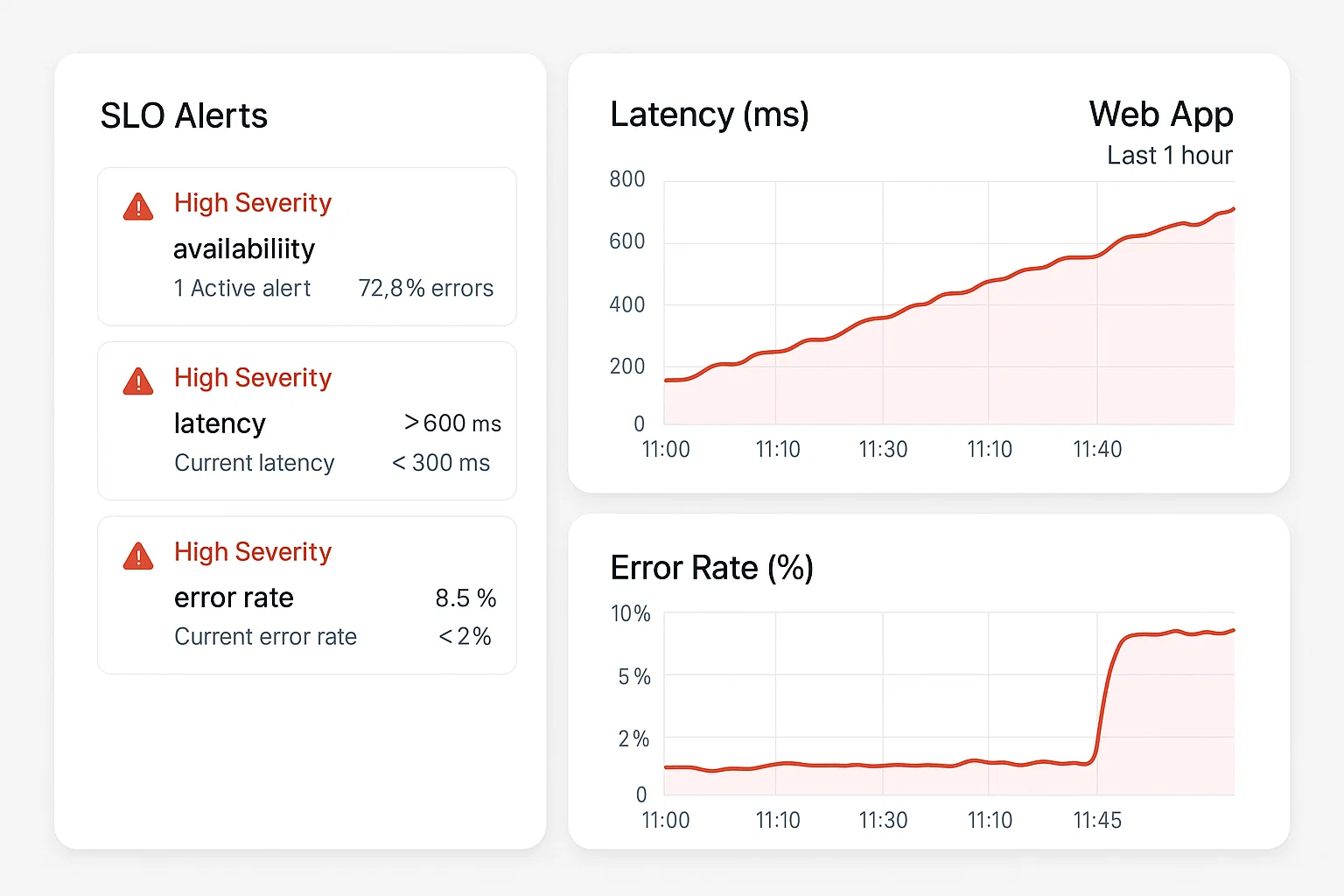
- Define RTO y RPO realistas.
- RTO (Recovery Time Objective): ¿cuánto tiempo máximo puedes estar abajo?
- RPO (Recovery Point Objective): ¿cuántos datos estás dispuesto a perder?
- Documenta ambos y alinea tecnología y presupuesto a esos objetivos.
- Piensa en “zonas y regiones” desde el día uno.
- Despliega servicios críticos en múltiples zonas de disponibilidad (multi-AZ).
- Para sistemas de misión crítica, evalúa multi-región activo-activo (o activo-pasivo con failover ensayado).
- Evita puntos únicos de falla en la arquitectura.
- Balanceadores, colas, funciones serverless y bases de datos deben tener redundancia.
- Diseña para degradación elegante: si falla una pieza, que el resto siga operando en modo limitado.
- Multi-cloud: cuándo sí y cuándo no.
- Sí para servicios frontales (web estática, CDN, DNS autoritativo) y datos replicados asíncronamente.
- Con cautela en bases de datos transaccionales y mensajería: la complejidad operativa puede superar el beneficio si tu equipo es pequeño.
- Observabilidad primero.
- Registra métricas de latencia, error rate y saturación con alertas inteligentes (SLO/SLA).
- Tableros ejecutivos: tiempo real para negocio (órdenes, pagos, sesiones), no solo métricas técnicas.
- Plan de continuidad y simulacros.
- Ten guiones de conmutación por falla y modo mantenimiento listos para activar en 1 clic.
- Practica game days y chaos testing trimestralmente; lo no ensayado, no existe.
- Diseño centrado en el usuario bajo falla.
- Mensajes claros en tu UI: “estamos experimentando demoras, tu pedido está a salvo”.
- Colas de trabajo y confirmaciones por correo/SMS para operaciones críticas.
- Cachés y “circuit breakers”.
- Usa caché de contenido y respuestas predeterminadas si tu servicio aguas arriba está intermitente.
- Implementa limites de reintentos y “corta circuitos” para no colapsar tu backend.
- DNS y CDN resilientes.
- DNS anycast con health checks y failover; considera tener dos proveedores DNS.
- CDN multiorigen con canary releases para desviar tráfico en minutos.
- Base de datos preparada para desastres.
- Backups verificados (restaura en un entorno “sandbox” mensualmente).
- Replicación cross-region para datos que lo ameriten; define qué colecciones/tablas son “tier 1”.
Checklist rápido para PYMES (prioriza de arriba hacia abajo)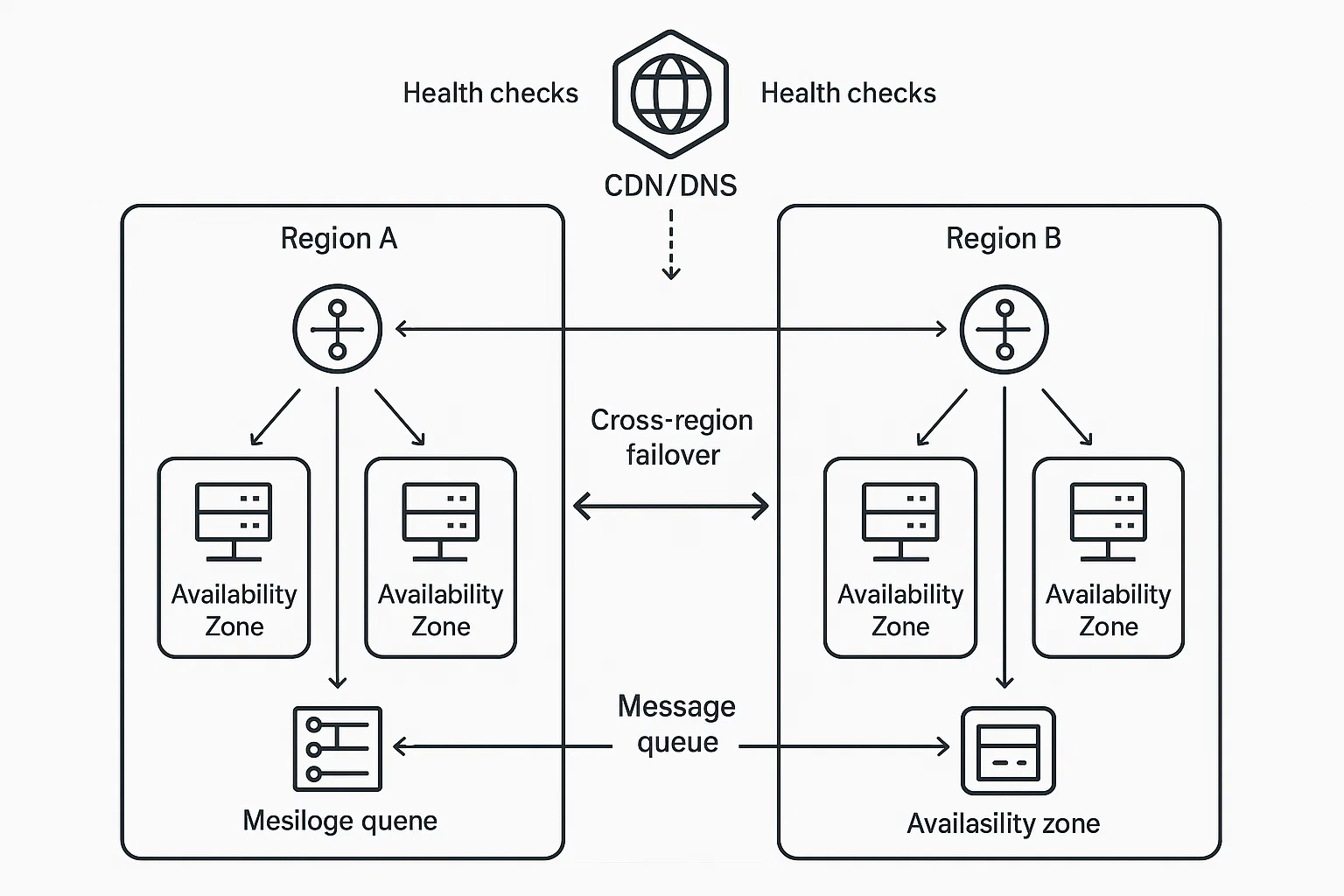
- SLA de negocio con RTO/RPO definidos
- Multi-AZ activado en cargas críticas
- Monitoreo con alertas por SLO y tablero ejecutivo
- Plan de contingencia (modo solo-lectura, colas, comunicación al cliente)
- Backups probados y réplica cross-region donde aplique
- DNS/CDN con failover verificado
- Simulacro semestral de caída regional
Qué puedes hacer desde hoy
- Mapea dependencias (directas/indirectas) de tu web, pagos y apps.
- Orquesta “modo degradado”: qué funciones se mantienen y cuáles se desactivan.
- Agenda un “fire drill” de 60 minutos esta semana: valida que tu equipo sepa qué hacer y a quién llamar.
¿Quieres traducir estas lecciones en disponibilidad real para tu negocio?
En www.SiteSupremacy.com diseñamos sitios web rápidos, estrategias avanzadas de SEO y arquitecturas en la nube con planes de continuidad, observabilidad y alta disponibilidad.
Escríbenos en www.sitesupremacy.com y preparemos tu infraestructura para el siguiente pico de tráfico (o la siguiente caída del proveedor).